The writer’s work tool is the written word, and the most efficient way to write words today is the modern computer. Digital text is an excellent system that have been evolving since the early 20 th Century, and has redefined the way we create and transmit information.
Understanding how digital text works is one of the most important skills a modern writer could have. Yet, most of them don't know what is behind the little letters that appear in the screen as they type into a computer. These letters, and the digital documents where they are written, remain a mystery to most writers.
But, not anymore. With this article, I intend to show the basics of how digital text works, from the zeroes and ones to the standards that define our “digital alphabet,” as well as the many text formats available for recording and transmitting ideas.
What is Digital Text?
Digital text is a sequence of bytes (groups of eight binary digits, which can be either zero or one), where each byte represents a letter of the alphabet. Computers are able to read these bytes and transform them into text when displaying in a screen, saving as a file, or sending to a printer.
When you open Windows Notepad, you receive a blank canvas for a plain text document. Plain text is the simplest computer file possible. It only contains characters, like letters, line breaks, and spaces. With each character made from a byte, text files are incredibly lightweight. Even a book as large as the Bible, written in plain text does not weigh more than a few kilobytes (thousands of bytes). By comparison, a single JPEG image or MP3 song can weigh millions of bytes (megabytes).
What defines a binary alphabet is a standard agreed upon by computer manufacturers and other corporations. In the early days of computing, the standard was ASCII (American Standard Code for Information Exchange). These were the characters as defined by the standard:
The biggest problem of the ASCII standard was its limited number of characters. It only supported characters commonly found in the English language, as well as symbols like period and comma, and invisible “control symbols” like spaces, line breaks, end-of-file symbols, and table border characters, used to draw lines in early systems that were based solely on text (terminal screens).
As computers became more common in other countries with other writing systems, new standards came up, like the JIS standard (Japanese), ASMO 449 (Arabic), and KOI8-R (Russian). Some systems supported one standard, but not the others, and different regions could not exchange information easily. For example, the binary number 11000001 in ASCII (extended) represents the letter Á (uppercase “A” with acute). In KOI8-R, it represents a (lowercase “a”), and in JIS, it represents チ (half-width Katakana character “chi”).
If you had a computer based on ASCII, and received a digital document written on a Japanese computer, you would not be able to read it without some kind of software conversion—which was not always easy to get and convert. Furthermore, it was likely that your computer could not display foreign characters because of hardware limitations.
Because of these problems, a universal standard was created. It was called Unicode, and it was agreed by all manufacturers of computers. Nowadays, we can interact with people from all around the world over the internet because of this standard. If you enter the Facebook page or the blog of a Japanese, a Russian, or a Greek, your computer is able to understand exactly what they wrote, and display the letters to you with precision.
For example, the phrase “How are you?” is encoded in Unicode as such:
| Binary | Text |
|---|---|
01001000 |
H |
01101111 |
o |
01110111 |
w |
00100000 |
|
01100001 |
a |
01110010 |
r |
01100101 |
e |
00100000 |
|
01111001 |
y |
01101111 |
o |
01110101 |
u |
00111111 |
? |
Each byte (eight-number group) represents a symbol, like a letter, a space, or a question mark. In some cases, however, characters may be represented by two or three bytes together―there can only be, after all, 255 possible combinations of eight numbers that are either zeroes or ones. For example, the Chinese character for water, 水, uses three bytes to be represented: 11100110 10110000 10110100.
A plain text file can contain written words in any language, as well as line breaks, spaces, and a few other symbols that are useful for a writer. For example, it has no-break spaces (a space that does not break when wrapping the text inside a screen), no-break hyphens, special symbols for punctuation, such as ellipsis (…), dash (―), etc.
But, sometimes we need more information in a file. For example, we need to announce that a certain part of the text is a paragraph, a title, a link, etc. We need metadata (information about the text, like author, date of creation), as well as display information (bold text, italic text, centralized text, etc.)
To solve this problem, markup languages were created.
Early Markup Languages
To indicate the role or appearance of a piece of text inside a plain text document, people came up with a system of markings. These markings were not part of the content, but were indicators of the document structure or appearance. For example:
This is a sentence written in plain text...
This sentence contains a <b>bold</b> word.
<title>This is a title</title>
Even today, webpages are written with this system. The HTML markup language contains tags for paragraph, metadata, formatting styles like bold and italic, links, and much more. Other styles of documents are also made like that, such as the Docbook format, the Text Encode Initiative, and many others.
“Markup” refers to the tags that are inserted between the text to either describe the text structure (paragraph, title, sections), or the text display (bold, italics, centered, etc.)
Besides this “tag” format of markup, we also have other styles of formatting to include this information inside a plain text document. For example:
Roff
.SH DESCRIPTION
This system uses dots with letters, that indicate the structure or display of the line that comes right after it.
Markdown
# Title
This is the text of a paragraph with *italic* and **bold** formatting, as well as [a link](path/to/link).
Rich Text Format (RTF)
{\rtf1\ansi\ansicpg1252\uc1\deff0\nouicompat
{\fonttbl{\f0\fnil\fcharset0 Arial;}{\f1\fnil\fcharset0 Times New Roman;}}
{\colortbl;\red255\green0\blue0;\red0\green0\blue255;}
\viewkind4\uc1
\pard\sa200\sl276\slmult1\lang9\f0\fs22 This is a sample RTF document.\par
LaTeX
\section{Introduction} % Section heading
This is a sample LaTeX document. You can format text in different ways, such as \textbf{bold}, \textit{italic}, or even \underline{underlined} text.
Using the information scribbled around the text, different types of software are able to interpret that a certain excerpt is a title, metadata (such as author and date), bold, italic, and much more. It can then convert the plain text document into other formats for digital and printed media. For example, by feeding a LaTeX processor the text written in the last paragraph, the output will look like this:

Rich Text (What You See Is What You Get)
The next step in the evolution of text markup is the word processor. Most writers don't know that the plain text file is quite different from the file used by a word processor like Microsoft Word and LibreOffice Writer. The main difference is: plain text shows the raw characters inside the file; word processors hide the markup away and show what they represent.
Documents in formats such as docx and odt are still plain text documents, but they are riddled with markup code that contains a great deal of information about the document. From the font format to embedded images, from tables to the visuals of typography, page style, and colors, the document generated by a word processor attempts to show, with as much fidelity as possible, the final result of a page.
In a word processor, this is what the text looks like to the user:
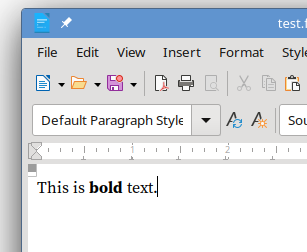
But, if you decompress the odt file, and look into its markup content, this is what you will find:
<text:p text:style-name="P1">This is <text:span text:style-name="T1">bold</text:span><text:span text:style-name="T2"> text.</text:span></text:p>
As you can see, regardless if you write in plain text formats, or in a word processor, you are using a kind of markup language or standard to represent the structure and formatting of your text. The word processor hides these markup tags from you and display only the final result, while text editors (also used to write code) show the raw content of the file, with markups. Both are desirable for different reasons.
Some advantages of writing in plain text file:
- Files are extremely light. A document with 25 characters written in a plain text format weighs 26 bytes. The same content in an
odtformat weighs twenty-seven thousand bytes. This is because, besides the text, it also contains a great deal of information about the document right from the start. - With a text editor, you know exactly what the document contains. Rich text formats are notorious for their ability to hide things from the user. In some cases, they can even hide macros and viruses. There are manners to protect yourself, of course; but, word processor documents are still a common way to infect unsuspecting users.
- You can edit a plain text file with pretty much any software. Most operating systems like Microsoft's Windows, Linux and BSD systems, and Apple’s own OSs have a native text editor that allows you to read, write and save a text document. But, to work on a rich text document like
odtanddocx, you need specialized software like MS Word and LibreOffice Writer. This may not always be an option. - You separate content and presentation. You can only use structural markup inside your text document, and let the software, or a third party, decide what each structural part should look like. This is common in HTML, for example, where a document can be associated with many different stylesheets that describe its appearance—one for print, one for small screens, one for large screens, etc.
In the past, many rich text formats like Word’s, and its competitors, used a non-standard markup based on binary elements, instead of plain text tags. Word, for example, included a bunch of binary information alongside the text to indicate the text’s markup, and only Word could decode this information. That way, Microsoft ensured the incompatibility of its documents with its competitors, and forced users to stick to Word.
But, many communities of users and programmers pushed to promote a universal markup language that could be decoded by anyone, and be human-readable, if needed. A good number of standards exist today, and, being open source, they can be implemented by software developers without the need to pay royalties. The odt format, for instance, is an open source format that can be interpreted by most word processors today.
A Note About PDF
PDF’s are an interesting case of document format that has a remote relationship with rich text formats, but is also quite different. The PDF is written as a combination of text and markup (in binary format). But, the PDF’s markup is extremely precise and detailed about what the page should look like. That way, regardless of the system or software that reads it, or the size of the screen, the page will always look the same. It is an ideal format to transfer documents that must be printed, because the printed result will be consistent.
PDF’s cannot be edited, and it is hard to read their markup. They can also transfer occult viruses, and are often used to infect computers of unsuspected users (especially when sent via e-mail). Yet, their usefulness is undeniable, and every writer should know how they work.
Direct Markup versus Global Styles
One notorious characteristic of word processors is the possibility to create global styles for structural elements, as well as the inclusion of direct formatting tags. Authors who don't know the difference between these two options often write documents with errors that, when converted to other formats for publication, create a whole range of headaches.
Global styles are predefined visual rules for elements. These rules affect all elements of the same type in the entire text. Word processors show the global styles in dedicated areas. The paragraph that is currently selected by the user receives the chosen global style.
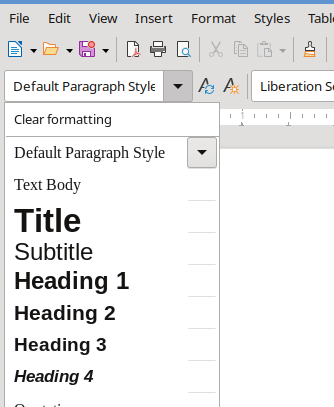
In the case of the example above: if I select a paragraph that contains a title, I can choose the global style selector “Heading 1” and, in an instant, the paragraph will be associated with the global style for titles of the first level. The appearance will change according to the style definitions.
But, not only the appearance is affected. From now on, the word processor will mark this paragraph as a title, and will use it to organize the text structure, as well as the output. So, now, if I open the word processor’s document browser, this title will be quickly accessible as a link. For a large document with countless titles and subtitles, the use of global styles makes it easy to navigate between different sections.
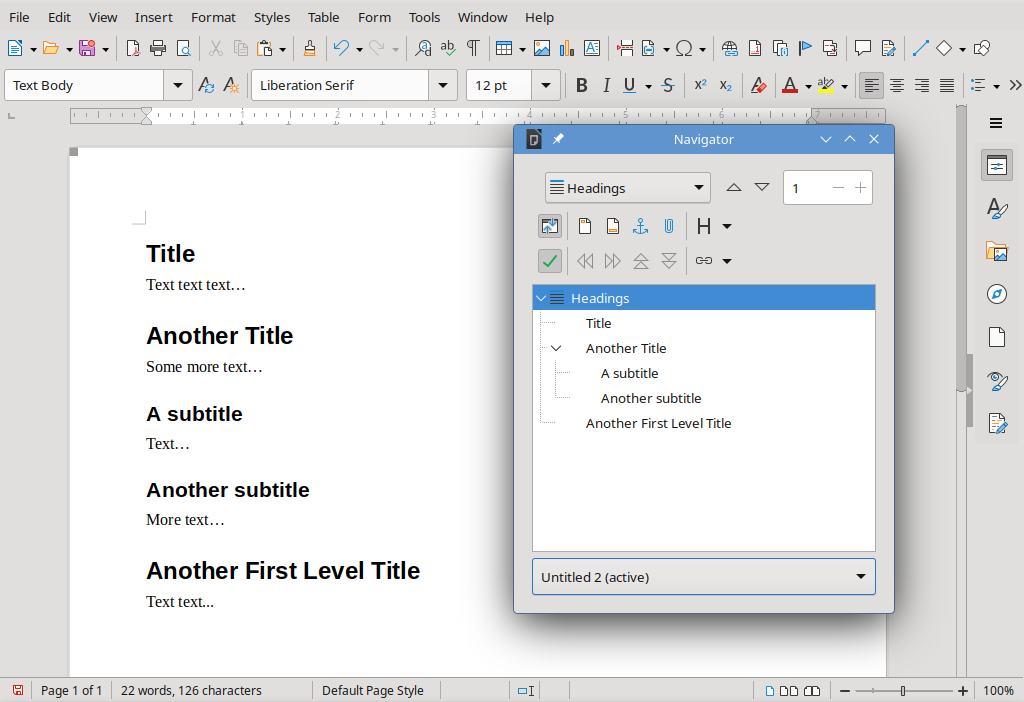
Another advantage of using global styles is that, if you change the visual of a global style, all paragraphs associated to this style will change automatically. That way, you don’t have to manually adjust each paragraph if you want to change the font or the color.
Meanwhile, direct formatting happens when you:
- Select a piece of text
- Click a formatting button without editing the global styles
In this case, the word processor will add a specific markup tag for the selected text, while leaving everything else the same way. Of course, direct formatting can be a problem, because, now, if you want to adjust the appearance of a text, you will have to manually change every little part where the direct markup has been added.
Direct markup can affect font appearance (color, size, font face), paragraph appearance (line height, justification, paragraph spacing), and much more. In general, it is bad practice to add too much direct formatting, and it is preferable to define global styles for the text.
Conclusions
I’m always shocked to see that many authors nowadays don’t know the difference between rich text and plain text, and don’t know a thing about markup languages. The raw material of their entire career is words, and, almost always, these words are written on a computer. How can they use something without understanding its basic functionality? It’s extremely important for any author to understand how text works on a computer, how it’s represented, and how the text structure and visuals are denoted in a text file.
Today, Most rich text editors are “what you see is what you get” type software: the screen tries to emulate the final result, showing bold, italic, line heights, paragraph distances, and other visual elements of the text. So, the user clicks a little button and, suddenly, his text is bold. Under the hood, the program is adding markup signs to indicate this. But, users don’t see the markup directly.
Yet, they need to know how these types of text work. Because, eventually, if they find any kind of problem with the file, or difficulty in its automatic conversion, they will know how to solve the problem.